
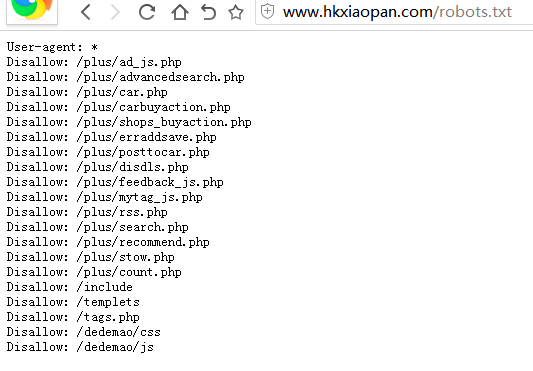
Robots文件并不是一个像W3C那样指定网络规范协议,http://www.yixiin.com/photo/而是众多搜索引擎约定俗成的。下图显示的是我们网站的robots文件内容。第一行的User-agent: *的意思是以下的Disallow命令是针对所有的搜索引擎的,也可以改为针对某一单独的搜索引擎。Disallow后的内容则是不允许搜索引擎爬取收录的内容。
虽然知道了robots文件的意义是什么,但是robots文件对于网站seo优化都有什么用呢?robots文件对于网站seo是有着一定作用的,要对其熟练的进行运用,主要有以下五个方面促进网站优化推广,因为robots文件是针对搜索引擎的,所以运用好能够增加搜索引擎爬取网站的体验度从而增加网站收录量。
1. 屏蔽网站的空、死链接
由于网站内容的修改以及删除,容易导致网站内的一些内链失效变为空链或者死链。通常我们会对网站定期检查空链和死链,将这些链接提取出来,写入robots文件之中,防止搜索引擎爬取该链接,间接提升搜索引擎的体验。该种方式是有效的,因为修改已经收录的内容时会使得搜索引擎重新的爬取修改过的网页,再次判断是否进行收录,如果没有继续收录了,那么就得不尝试了。
2. 防止蜘蛛爬取网站重复内容
因为网站很多的动态页面搜索引擎时无法收录的,所以很多时候我们需要对于这些动态页面进行制定一个静态的页面以助于搜索引擎收录。这时候就让搜索引擎不要爬取某一些重复的内容,可以减少站内的页面关键词权重竞争。
3. 防止蜘蛛爬取无意义内容,浪费服务器资源
网站上是有很多的内容都是一些无意义的内容,例如网站的各种脚本代码、css文件和php文件等等,这些文件对于网站优化都是无意义的,爬取这些网站不仅不会收录,而且还会浪费服务器的资源。上图中很多禁止访问的内容都是这类无意义的文件目录。
4. 保护网站隐私内容
网站有很多的页面都是有着一定隐私的,例如一个用户接受的推送又或者是购物车等等,这些链接虽然在一个页面之中有,但是显然是不希望搜索引擎爬取的内容。
5. 有利于网站调试http://www.yixiin.com/news/
在网站初步上线前都会有着一定的错误,需要一段时间的调试再对搜索引擎开放爬取,在调试期间就可以将robots文件设置为对于所有的搜索引擎都处于拒绝爬取状态,等所有的错误都解决后再修改robots文件。
注意细节:每次修改robots文件之后都需要到搜索引擎站长平台去提交robots文件更新提醒,因为搜索引擎更新网站的状态都是需要一定的时间,只有人工提交才能够让更新后的robots文件like生效。